
��������ͷ��������û����ģ�ͣ������ҿ��ֻ��������ˡ�
����ǰ��OPPO���ô�ģ���������������֣����vivo���������ֻ�AI��ģ��;
����С��������ֱ�ӽ���ģ�͵��������ֻ�ϵͳ……�侺�����ҳ̶ȣ���������оƬ����

��������������?
��������ԭ���������ն��Ѿ���Ϊ�˸���AIGCӦ�õ����“��̲ͷ”��
��������ͼ�����ɴ�ģ�ͽӶ������ر������ֻ�����ʮ�ڲ�����Stable Diffusion�����ֻ��Ͽ�������һֻ��ëС����
������ͼԴ��Android Authority
�������ֻ�������ʮ���ڲ�����ControlNet����������һ����ͼ��ṹ��AI�羰�գ�
��������ı����ɴ�ģ����Ҳ���ȿֺ���Ƴ����ֻ���Ӧ��——
��������������һ�ԡ���������APP����������OpenAI���ƶ���ChatGPT��Llama 2�ֻ���Ҳ�ڼӼ����С�
�������ڣ���һ�������ն˴�ģ���ȳ�֮�У���ײ����Ӳ���������ֿ�ʼת����
�����Ӹ�ͨ��ƻ�������µ�оƬ���̷����ᣬ��һ����ǿ����Ӳ���Ի���ѧϰ�ʹ�ģ�͵�֧��——
����ƻ��M3������“��ʮ�ڲ���”����ѧϰģ�ͣ���ͨ������X Elite������8 Gen 3�����Ѿ��ֱ�ʵ�ֽ�130�ں�100�ڲ�����ģ��װ�����Ժ��ֻ���
���������ⲻ��������֧�ֻ���ͨ�����ֲ���������ʵʵ���ڵ��˿����Ӧ�õij̶ȡ�
��������ͨ�ֳ���ʾ���ֻ��еİ��ڴ�ģ�ͶԻ�
������ʮ�ڵ����ڣ�����������ƶ���AIģ�Ͱ�ʾ�˸��õ����飬��Ҳ��ζ��һ���������ս——
�����������Խ�������������ս����Ĵ�ģ��ʱ������֮Ϊ��ģ��ʱ������
������ģ��ʱ�����£�оƬ���̾���Ҫ��γ��ƴ�ģ����ֲ�����ն����ٵ�������������ĵ�����?
������һ���أ���ģ�͵ij����ָ��ײ�оƬ��ƴ�������Щ�ı�?
������ʱ���������飬�ú÷���һ���ˡ�
������ģ��ʱ������Ӳ��Χ��AI����
�����Ӵ�ģ�ͷ籩����֮���������ͳ�Ϊ�˿Ƽ�Ȧ�Ľ��㻰�⡣
�������������OpenAI����ΪDevDay��“Զ��Ԥ��”�Ĵ�ģ�͵���������������ȫ�߲�Ʒ崻���ʷ������¹ʡ�
����������ƶˣ��ƶ��ն˵�������Ϊ���ޡ���Ҫ�Ѵ�ģ��װ���ֻ�������������Ȼ�����˵�һ����ս��
�������㵥Ԫ֮�⣬�����ڴ浥Ԫ���Ǵ�ģ�ͽ��ֻ����ٵĵڶ����ѹأ���ģ��������Ҫ����������Դ��֧�ţ����ͬʱ���ڴ��С���������ݴ����ٶȵ������Լ��������ȶ��ԡ�
�������⣬���ֻ����ܴ�ģ�ͣ�Ҳ����ش����˸����ѹ�������оƬ�ܺij�Ϊһ��ؼ���
�����ڸ����̵�����̽��֮�У����ǿ��Թ۲쵽�����֮��Ŀǰ��Ϊ����Ӳ��·��
����������Ӳ�����֡�
������ͨ�����Ƴ��ĵ���������8�ƶ�ƽ̨���ͱ���λΪ��ͨ“��ר��Ϊ����ʽAI������ƶ�ƽ̨”��
�����ܹ����ն˲�����100�ڲ�����ģ�ͣ�����70�ڲ���������ģ�ͣ�ÿ��������20��token��
������֮ǰ����Ʒ������������8����Ҫ�ı仯�����������ն˲�AI�������ٵĸ�ͨAI���档
�������AI�����ɶ��Ӳ����������ɣ�������ͨHexagon NPU��Adreno GPU��Kryo CPU�ʹ��������ࡣ

������������ġ���AI��������صģ���Hexagon NPU��
������ͨ������������ʾ��Hexagon NPU�����ܱ����ϣ���ǰ����Ʒ��98%��ͬʱ���Ľ�����40%��

����������ԣ�Hexagon NPU������ȫ�µ��ܹ��������ʸ��������ʱ���ٶȡ���ǿ�����������ͶԸ�������Transformer�����֧�ֵȵȣ�ȫ��������Hexgon NPU������ʽAI����Ӧ������ʹ���ֻ��ϵĴ�ģ��“���”�û����ʳ�Ϊ���ܡ�
����Hexagon NPU֮�⣬����������8��Sensing Hub(����������)��Ҳ���˹���������һ����NPU��AI�������3.5�����ڴ�����30%��

����ֵ�ù�ע���ǣ��ٷ��ᵽ��Sensing Hub�����ڴ�ģ�����ֻ��˵�“���ƻ�”����ʱ���ָ�֪��Sensing Hub���ģ��Эͬ�������������û���λ�á���ȸ��Ի����ݸ��õ�Ϊ����ʽAI���á�
���������ڴ淽�棬����������8֧��LPDDR5X��Ƶ�ʴ�4.2GHz��ߵ���4.8GHz������77GB/s���������Ϊ24GB��
������������ݴ����ٶȣ�����Ĵ�����Ҳ����ζ�ŵ���������8�ܹ�֧�ָ�������ӵ�AIģ�͡�
�������ң��˷���ͨ���ڴ��Hexagon NPUʸ����Ԫ֮��������ֱ��ͨ������һ�������AI����Ч�ʡ�
����ǡ����������ڼ䣬SK����ʿ���ر����������ƷLPDDR5T�Ѿ��ڸ�ͨ����������8����������ܼ���������֤���ٶȴﵽ9.6Gbps���ɴ˿��������ص���������8���ֻ����ڴ淽�滹�и����ѡ��

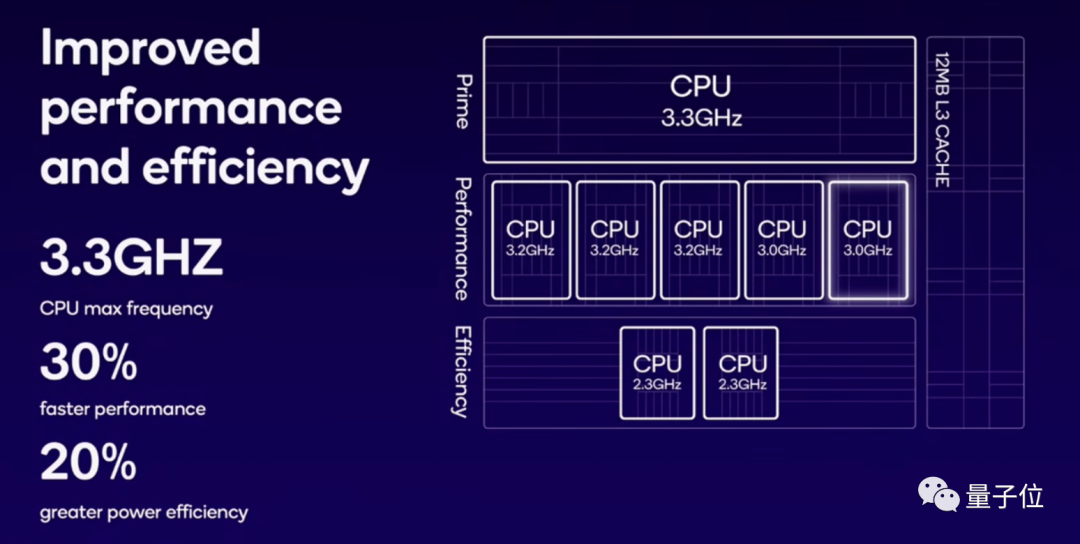
��������֮�⣬��CPU���棬����������8����“1+5+2”�ܹ�(1�������ġ�5�����ܺ��ĺ�2����Ч����)�������ǰ����“1+4+3”����1����Ч����ת��Ϊ���ܺ��ġ����г����Ƶ��������3.3GHz�����ܺ���Ƶ�����������3.2GHz����Ч����Ƶ��������2.3GHz��
�����¼ܹ��£�Kryo CPU���������30%�����Ľ�����20%��
����GPU���棬����������8�������ܺ���Ч�����ʵ��25%��������
����ֵ��һ����ǣ�AI����֮�⣬����������8��ISP�����ƽ����������ģ�飬Ҳ�Ѹ�ֲAI����
�������ڣ���ͨ����֪ISP�ǽ����ģ�
����֧�ֶ��12�����Ƭ/��Ƶ֡ʵʱ����ָ�;
�����ں�����ʽAI������֧���������պ���Ƶ�༭;
����֧������AI��������Ƶ��ɾ������Ҫ���˺���;
����֧��AI��չ��Ƭ;
����……
�������ƽ����ͬ����5G AI�������ļӳ֣�ͨ�������ź������Ժ�����ȣ�AI�ܹ��������ߴ������ӳٵ�����ָ�ꡣ
�����ɴ˿������ڴ�ģ�ͽ��ֻ��Ĺ����У���ҵ����ߵ�Ӳ�����֮�����Դ����������ܽ
������һ��������������ڴ桢�ܺ���Ҫ�ص�������������ƽ�⡣
�������������AI������Ӳ������AI���������������Ľ�ϡ�
������������˵Ӳ�������ܽ����ģ����ֲ�������ն˵Ĺؼ��ѵ㣬��Ҫ�������������Ӧ�ã�����Ҫ��������һ���ż���
�������ʹ�ģ�����������ż�
��������ż���������Էֽ�Ϊ�������⣺
�����������¡���������ģ�ͣ���ο���ʵʱ��װ���ֻ�?
����װ���ֻ�����Ҫ��ο���װ���ֻ�����������ն�?
����Ҫ�������������⣬�Ͳ��ܽ�����Ӳ�������֣���ͬ��Ҫ��������������������
�������ȣ���Ҫ����ǿ�����ն˶Բ�ͬ��ģ�͵�������������ʹ�Ǽܹ��㷨���ڲ���Ҳͬ����װ���ֻ���
������ʹ���´�ģ���������Ԥ�ڣ�ҲҪ��ȷ���ڲ�Ӱ�����ܵ�����£���֮Ӧ�õ������նˡ�
�������������Ը�ͨΪ����
�������������ֻ�������10�ڲ���Stable Diffusion�������ٻ�������8 Gen 3������ڲ�����ģ�ͣ�����ʵ���ϻ��벻��һ����������——
����AIѹ��������
�������µ�AIѹ���������Ӹ�ͨ���귢����AI�����ϵļ�ƪ���Ŀ��Կ���һ�ߡ�
����������ƪ��NeurIPS 2023��¼�����ģ�����Ե�ǰ��ģ�͵�“��ʯ”Transformer�ܹ�������������ص��о���

����������ѹ��AIģ�͵�һ�־��䷽����Ȼ����ǰ��ѹ��Transformerģ�͵�ʱ�����׳���һЩ���⡣
������ƪ������������ַ�������Transformerģ�ͽ�����������ȷ��ѹ��Ч����ͬʱ����һ������ģ��������ܣ�ȷ��ģ�Ϳ�����“��С����”��
����Ȼ����Ҫ��ǿ��ģ�������ڲ�ͬ�����ն�֮���ͨ���ԣ���һ��������ء�
�������ڴ�ģ�Ͷ��ԣ���һ��Ӳ���豸Ǩ�Ƶ���һ��Ӳ���豸����û����������ô���ס�
������ͬ�ļ���ƽ̨֮�䣬Ӳ����������������ܴ����������еĴ�ģ�ͣ��ŵ��ֻ��ϻ��治һ�������������С�
��������Ҳ�����谭��ģ��������ࡢ�������ӵ������ն���ص���һ��ԭ��
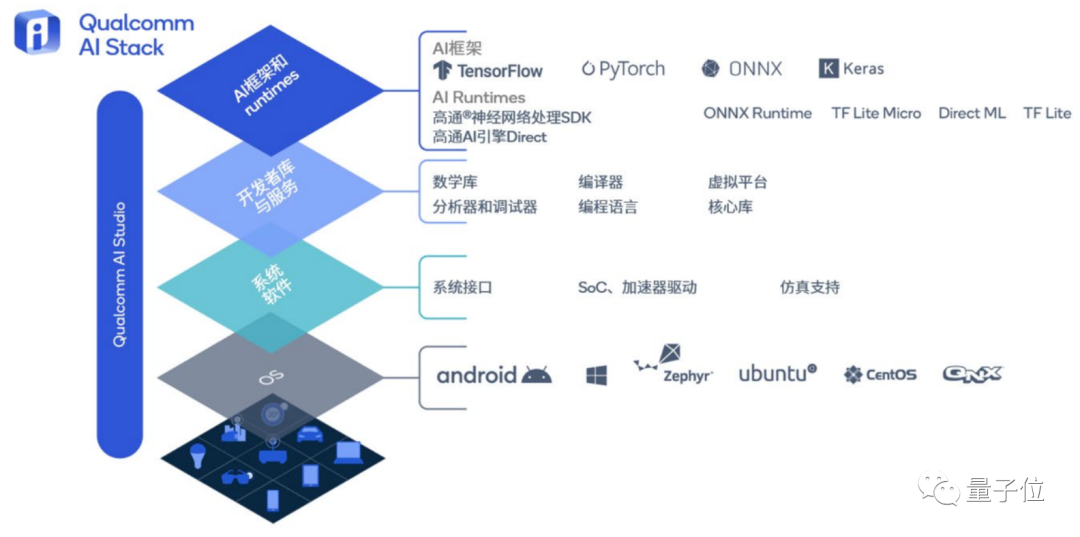
�����Դˣ���ͨ������һ��“ת����”һ���Ľ�ɫ����ͨAI����ջ��
��������һ�������˴���AI�����Ĺ��߰���ȫ��֧�ָ�������AI��ܡ���ͬ����ϵͳ���������ԣ�����������AI�����������ն��ϵļ����ԡ�
����������ˣ���������ջ��������ͨAI Studio���൱�ڽ���ͨ������AI�����ɵ�һ��ֱ�ӽ��п��ӻ�������
�������У���AIģ����Ч���߰���ģ�ͷ�������������ܹ�����(NAS)�ȶ������档
����AI����ֻ��Ҫ���������ơ��Ż���������“��һ������”�����ܿ���ת��������������ϵͳ��ƽ̨��Ҳ�������е�������Ʒ��
����ֻ��Ҫһ�ο����������Ǵ�ģ�������Ŀ��������������ڶ��ƽ̨���У�����Ҫ������������⣬��Stable Diffusion���Ѿ��������У�����ƽ̨Ҳͬ��������ȡ�����ˡ�
��������һ�����������ǽ����ڲ�����ģ�������ֻ����������ܽ�������������XR��PC����������

����ԭ�����豸���ͷ����ȱ��Ҳ�ܻ�Ϊ���ƣ���һ�����ٴ�ģ����������ء�
�����ܽ���������ģ����ֲ�������ն�����ļ�����������Ӳʵ����������Ҳͬ����Ҫ����������
�������ԣ������ڴ�ģ��ʱ�������ƴ������ƶ�����Ӳ�����̶��ԣ�������β���ץס����ѵõĻ���?
��������˵��������Ҫ�����ǰ������������ȷ����ģ��ʱ�����������ڼ����˳�֮��?
������ģ��ʱ����Ҫ�������ն�оƬ
����һ��ʱ����һ��ʱ���ļ���ܹ���
�������ѧϰʱ������ˣ�������Ӱʱ������ˣ���ģ��ʱ���������——
����������Ӳ������ģ��ʱ�����µ������ն�оƬ���б��Ѿ���Ȼ���䡣
����һ���棬����Ӳ�����ܶ��ԣ�оƬ�Ѿ��ӵ�����Ӳ�����ܶԱȡ��������������ļ��㣬��ת��ɶ�AI�����ı�ƴ�������Ƕ�AI��Ӳ������������ȫ��Ҫ��
��������ת�䣬�Ӵ�ģ�ͳ��̾�ͷ�ļ�������ջ�仯���Կ���һ�ߡ�
��������Ϊ������ҿƼ���ͷ���Ƴ��̣����ڿ�ʼע����AI��Ӳ����ϵļ��������ģ��ѵ���ȡ�
��������ǰ���õ�һƪѵ���о��У���ϵͳ�����˴�ģ����FP8������ѵ����Ч��������ͬ��Ӳ���ɱ��£�ѵ�������ģ�Ĵ�ģ�͡�ͬʱȷ��ѵ��������ģ�����ܡ�
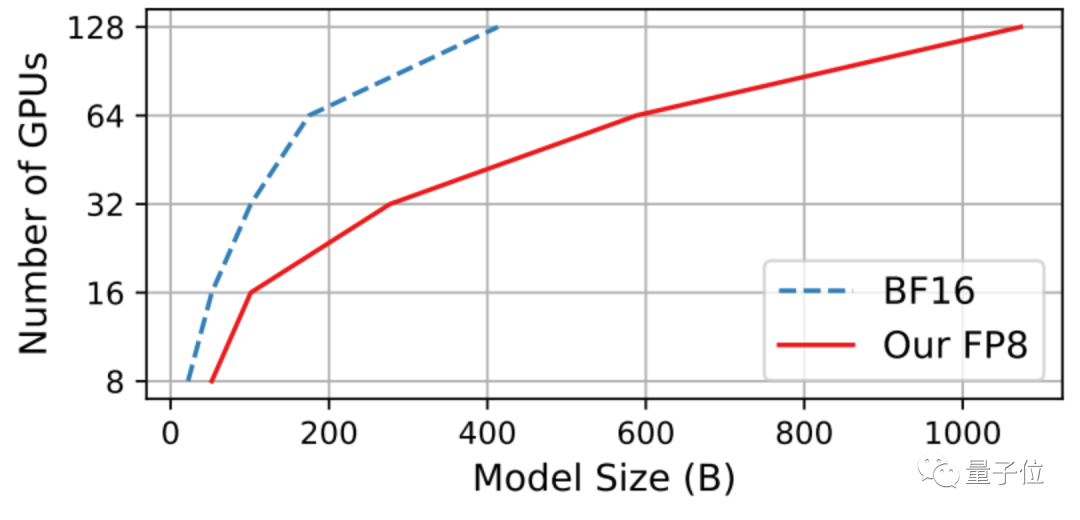
������ͼԴ����FP8-LM: Training FP8 Large Language Models
������AI�㷨�о����Ƶ�OpenAI�����س�����о������ʼ��Ӳ������ļ���������
������Ȼ���Ӳ�ͬ�Ƽ���ͷ�����о����ܿ�����������������������ʱ��������һ�ŵ��ƾ���ץס���������������ֵ�ĸ��ʣ������Խ��Խ�͡�
���������ͣ����“Ӳ����˾���о��������˾�����㷨”�ĽΣ��Ʊ�ֻ�ᱻ������������ij��̳������ڡ�ģ��ʱ����ʧȥ���еľ�������
��������Ӳ�����������Ƶ�оƬ��˾��������ˡ�
��������Ӳ�����ܵ��������⣬��ʱ�����չ��������ջ��������Ӳ����ϵ�AI������ͬ�����ɻ�ȱ��
������ͨ��ǰ�����Ƴ��İ�Ƥ���о��ᵽ������ģ�Ͳ����������ն��ϣ�����Ҫ����Ӳ����Ҳͬ����Ҫ����ģ���Ի��������������⡣
��������ȵȴ���ģ�ͳ���ȥ�����Щ���⣬��ͨѡ���Լ���������������о������³ɹ�Ҳͬ��ʵʱд�����ķ���������

����ֻ�����������ܸ��õ��˽��㷨���������Ӳ�������Ӷ����õ�����оƬ�����ܡ�
������һ���棬�������������ޡ��û���Χ������ն˶��ԣ�δ�������Ʊ�Ȼ���컥���������ζ�ţ���ƽ̨�����Ի��ΪAI��������Ĺؼ���
�������ֶ��ӽ������������Ϸ�����Snapdragon Seamless�������ܿ���һ�ߡ�
�������ǽ�ƽ���ϵ���Ƭ����������“һ��ƽ��”��PC���ڵ����Ͻ��п��ٴ�����
����������Ϻ��ܽ���Ƭ����һ���豸�ϴ�����PC�ļ��̸�����������
������ʹֻ��һ���豸ӵ�м��̺���꣬Ҳ�ܶԸ����豸��������ƣ�������AI����Ҳ���ϰ��ڸ����豸֮������ʹ�á�
�����������ݴ����ӳٲ��������δ�����ԣ���ͨ���ն�Э���ͻ������Ʊ��������ն˵���һ��δ����
���������ֻ���PC�Ȳ�ͬ���ն��豸֮����Թ������ݡ���������ͬһ���豸�ڲ�ͬ�IJ���ϵͳ֮�����һϵ�����������������ֻ���PC����Ƶ�ڶ���֮�����л���
����֮ǰֻ�����ֻ�����ʹ�õ�AIӦ�ã���������ϵͳ������չ��ǧ��̨�����ն��豸�ϣ�����PC��XR��ƽ���������
��������һ������ģ�;Ͳ��ٻ�������ijһ̨�豸������ijһ������ϵͳ�������ܿ��ٽ��Ѿ���һ���ն���ʵ�ֵ�AI�����������õ������豸�У�����ʵ��“����Կɴ�ģ��”�IJ�����
�����ܽ��������ڴ�ģ��ʱ���£�AI���̲�����Ҫ�߱���Ӳ����ϵ�����������Ҫ��ǰ���������ն����ﻥ����δ�����ԡ����ӡ��������ٴ�ģ���ڳ����µ����Ӧ�á�
������ͨ�Ѿ��������Լ����ж�·����
��������������ͬ��ҵ���ԣ�����Ҫ�ڳ�����̽�������ļ�ֵ���ſ����ڡ�ģ��ʱ�������ҵ��µij�·��
����(����ת��������λ���ں�)

������ҵ��Ѷ����ҵ��̬��ҵ��۵㡢����ɷ����ʼ���news#citmt.cn����#����@����
����������...
������������ϵ������������������վ��ͼ��������ϵ�����±�������������
��ICP��18015839��-1רעIT��ҵ������IT��ҵ�� IT��ҵ��̬��ֵ����ƽ̨|IT��|IT�|IT���|ITֱ��
������ʾ:�������ݽ����Ķ�,������Ͷ�ʽ���,������Դ���
IT��ҵ��&WWW.CITMT.CN © 2016-2024

