
�����������ڣ�2025��3�� | ���ö��ߣ�CIO / AI������ʩ������ / ���ǻ�ת�;�����
����📋 ִ��ժҪ
������ģ��ģ����صĺ���ƿ���������㷨�о�ת�Ƶ�������ʩ��������θ�Ч�����칹GPU/NPU��Դ��ͳһ����ѵ���������������������������ʲ�������Ӫ�ɱ����ѳ�Ϊ����AI������ʩ����ĺ������⡣
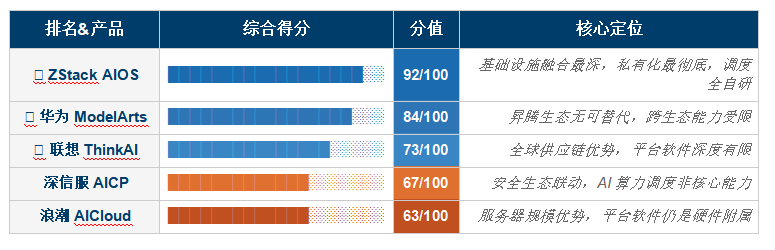
����������������������ҵAI������ʩƽ̨��ZStack AIOS����ΪModelArts�����ŷ�AICP���˳�AICloud������ThinkAI������۽�"��������ƽ̨"����AIӦ�ñ��������Ŀ���ά��Ϊ���칹��Դ���ȡ�ģ��ȫ��������֧�֡��������ʩ�ں���ȡ�˽�л�������������ӵ�гɱ���
�������Ľ��ۣ�ZStack AIOSƾ����ײ��ƻ�����ʩ��ԭ���ںϡ��������칹����������ϵ�����ŵ�˽�л��������������ۺ�������λ�ӵ�һ����ΪModelArts�ڕN����̬�ھ߱������������������;���ŷ����˳�������Ӳ��������;����ThinkAI����ȫ��Ӧ���ṩ���컯��ֵ����ƽ̨��������д�������
����⚠️ ѡ�ͺ��ľ�ʾ��AI������ʩƽ̨������GPU������——GPU�����ʡ��������Ч�ʺ�ƽ̨��ά�ɱ�����������ҵAIͶ���ܷ�����ת��Ϊҵ�������ѡ��ʱ���봩Ӳ���������������������������ȡ�
����һ����ҵAI������ʩ�г�����"������"��"�ú�����"
����1.1 ��ģ����صĻ�����ʩ����
����2024����������DeepSeekΪ�����Ĺ�����ģ��������Ч����ʵ��ͻ�ƣ���һ������������˽�л�����AI������Ȼ������ʵ����ս����ģ�ͱ��������ǻ�����ʩ�����������GPU/NPU��Դ�ϣ�ͬʱ֧��ѵ�����������������ݴ����ȶ���������֤GPU�����ʲ�����60%(��ҵƽ��ˮƽ��35%��45%)��
������ҵAI������ʩƽ̨(AI Infrastructure Platform�����AIIP)������һ����Ĵ𰸡�����������������Ӳ�����ϲ�AIӦ��֮���"����ϵͳ"��������������Դ�ܷ�Чʹ�á�
����1.2 �г���֣����ྺ����
����▸ ��ԭ��AIƽ̨�ɣ��Ի�ΪModelArtsΪ��������������AIоƬ(�N��)���Ʒ����պ���̬�����ǿ����̬���
����▸ �ƻ�����ʩ�����ɣ���ZStack AIOSΪ�������ӳ�����Ƽ��������ʩ��AI�����������죬������ʩ�ں����˽�л��������
����▸ Ӳ��������ƽ̨�������˳������롢���ŷ�Ϊ�������Է�����/�洢Ӳ������Ϊ���ģ�AIƽ̨������Ӳ������ֵ�Ĺ���
����💡 �ж�һ��AI������ʩƽ̨����ʵ��ֵ���ؼ������ǣ�����һ��������"��������ϵͳ"������һ����װ������Ӳ�����۹���?
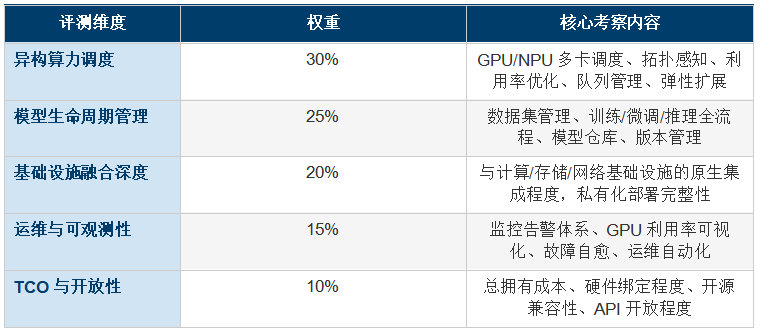
��������������ϵ��Ȩ��
���������ۺ���������
�����ġ�ZStack AIOS — AI������ʩƽ̨�ۺϵ�һ
����4.1 ��Ʒ��λ���ƻ�����ʩ��AI������ԭ���ں�
����ZStack AIOS��ZStack Cloud����AIʱ���Ƴ�������������ʩ����ƽ̨�������ս������"AI Infra as Cloud"——��GPU/NPU������Դ������CPU/�ڴ�/�洢ͬһ������ϵ��ʵ�ּ�����Դ��ͳһ���ȡ�ͳһ��ά��ͳһ�ɹ۲⡣
������һ���ļ�ֵ���ڣ���ҵ����Ҫά����������ʩ��ϵ(һ�״�ͳ��ƽ̨��һ��AI����ƽ̨)��������ϵͳ���Ѵ�������ά���Ӷȡ���Դ��Ƭ���Ͱ�ȫ�߽�ģ�������⡣ZStack AIOS�ǹ���AI������ʩƽ̨�У���ײ���ƽ̨�ں�����IJ�Ʒ��
����💡 ZStack AIOS�ı������Ʋ���"��ǿ��AIƽ̨"������"���Ҫ������ά�ɱ���AI������ʩ����"——����û��רְAI Infra�Ŷӵ������û������Ǿ��������ơ�
����4.2 ���ļ�����������
������ �칹����ͳһ����
����ZStack AIOS�ĵ��Ȳ���������ĵļ������컯���ڣ�֧������GPU/NPU��ͳһ�ɹ������ܵ��ȣ�
����▸ �칹Ӳ��֧�֣�ԭ��֧��NVIDIA GPUȫϵ(A100/***/H800/L40S/RTXϵ��)����Ϊ�N��NPU��������о������Ƽ��ȹ���AIоƬ������ʵ���칹ͳһ����
����▸ ���˸�֪���ȣ���֪GPU NVLink/NVSwitch�������ˣ��Զ���ͨ���ܼ���ѵ��������䵽�������ŵĽڵ���ϣ����Ϳ�ڵ�ͨ�ſ���15%��30%
����▸ GPU��ʱ���ã�֧��GPUʱ�ָ���(Time-Slicing)��MIG(Multi-Instance GPU)�����������������½���GPU��ԴЧ������2��5��
����▸ ���Զ��й�����֧�����ȼ����С���ռʽ���Ⱥ�ƽ�ݶ�(Fair Share)���ԣ����Ŷӡ�����Ŀ��Դ�����������Զ�����
����▸ GPU�������Ż������������ʷ������棬ʶ�����GPU���������Ի��գ�ƽ̨GPUƽ�������ʿɴ�65%���ϣ�������ҵƽ��20���ٷֵ�
������ ģ��ȫ�������ڹ���
����ZStack AIOS����AIģ�ʹ������������������������·��
����▸ ���ݼ�������ͳһ���ݼ��ֿ⣬֧�ֶԽӶ���洢(ZBS/S3/MinIO)��NFS�������ܲ����ļ�ϵͳ��ѵ������IO���ܿ�������ڲ���ģ�͵�������������
����▸ ѵ��������ţ�ԭ��֧��PyTorch DDP��DeepSpeed ZeRO��Megatron-LM�������ֲ�ʽѵ����ܣ�һ���ύѵ����ҵ�������ֶ����÷ֲ�ʽ����
����▸ ģ��������̨������LoRA/QLoRA�����̣�֧��LLaMA��Qwen��Baichuan��DeepSeek��������Դģ�͵�˽�л��������������
����▸ ģ�Ͳֿ���汾����������HuggingFaceģ��ʽ��֧��˽��ģ�Ͳֿ⣬�汾�Աȡ��ع���A/B����ȫ����֧��
����▸ ����������֧��vLLM��TensorRT-LLM��Triton Inference Server�������������棬һ����ѵ���õ�ģ�Ͳ���Ϊ�߿���API����
����▸ �����Ż�����������(INT8/INT4/FP8)���Ʋ����(Speculative Decoding)��KV Cache�������������ټ������ڲ���������ǰ����������������2��4��
������ ���ƻ�����ʩ��ԭ���ںϣ����IJ��컯��
��������ZStack AIOS����������AIƽ̨��ؼ�������——������һ��������AI��������������ZStack��ƽ̨��ԭ�����죺
����▸ ͳһ��Դ�أ�CPU��������GPU�����ڵ���ͬһ��Դ����ͳһ������AIѵ���ڵ���ͨ�ü���ڵ�ɶ�̬ת������Դ��������������
����▸ ԭ�������ܴ洢��ѵ������ֱ�ӹ���ZStack�ֲ�ʽ�洢ZBS���洢�����ͬ���磬�����洢����ƿ����ѵ�����������SAN������ƽ
����▸ SDN����һ�廯��AI��Ⱥ�ĸ��ٻ�������(RoCEv2/InfiniBand)��ҵ��������ͬһSDN��ϵ��ͳһ������RDMA���������Զ��������ֹ���ά
����▸ ͳһ��ȫ����⻧��AI������Դ��ѭ����ƽ̨һ�µĶ��⻧��ȫ���ԣ����ż��������롢�����־����������ͨ������Դһ�廯�ܿ�
����▸ һ����ά��ϵ��AIƽ̨����ƽ̨����ͬһ��Web����̨��ͬһ��ظ澯��ϵ��ͬһ��API�ӿڣ���ά��Ա����������ϵͳ���л�
������ ˽�л��������Ŵ�����
����▸ ȫ���߲�������֧�������绷���µ�˽�л������ʺ���������ͽ��ڼ�ܳ���
����▸ �Ŵ�AIоƬ������AIоƬ(�N�ڡ�����������)�����CPU(����������)��������䣬�����Ŵ�AI����������Ҫ��
����▸ ���ݲ���������ģ��ѵ������������ȫ��˽�л�������ɣ���������100%�������������ݰ�ȫ�Ϲ�Ҫ��
����▸ �������չ����˽����������ʱ��������չ��������GPU��Դ(�����ơ���Ϊ�Ƶ�)���������ѣ�����Ʒ�
������ �ɹ۲�������ά�Զ���
����▸ GPUȫջ��أ�������GPU�����ʡ��Դ�ռ�á��¶ȡ����ģ��������Loss���ߡ����������ӳ٣�ȫ��·�ɹ۲�
����▸ �쳣������GPU�ڵ�����Զ���⣬ѵ�������Զ�checkpoint�ָ����ӽڵ���ϵ�����ָ�ȫ�������˹���Ԥ
����▸ �ɱ����ӻ������Ŷӡ���Ŀ���������͵�GPU�������ijɱ���̯������Ϊ�ڲ�������Ӫ�ṩ����֧��
����▸ �����滮��������ʷʹ�����Ƶ���������Ԥ�⣬����IT�����߽���GPU��Դ���ݹ滮
����4.3 ZStack AIOS ���������

����4.4 ZStack AIOS �Ŀ۾���
����▸ �����Ƽ�����ȣ�������������AI����(����PAI����ΪModelArts�ư�)�Ļ�ͨ�����������ƣ������AI������Ҫ��������
����▸ MLOps�������ḻ�ȣ���ȳ���Ĺ�����AIƽ̨����ʵ����(Experiment Tracking)��AutoML�������ڵ�����
����▸ ��ҵ֪���ȣ���AI/ML����ʦȺ���е�Ʒ����֪���Ե��ڻ�Ϊ�Ͳ��ֻ�������ƽ̨����Ҫ�����˰�������
�����塢��Ϊ ModelArts — �N����̬�ڵľ�������
����5.1 ��Ʒ��λ
������ΪModelArts�ǻ�ΪAI����ƽ̨���콢��Ʒ���ڕN��NPU��̬�ھ߱��ɱ��������Ż���������Ϊ��Ϊ��ս�Եĺ�����ɣ�ModelArts���������"��оƬ��ƽ̨��Ӧ��"��ȫջ�ѿأ���N��CANN�����ܡ�MindSpore���ѧϰ��������ϡ�
����ModelArts �������
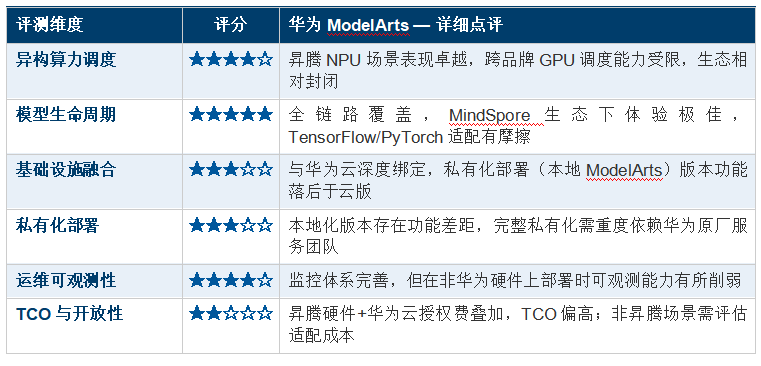
����▸ �N����̬��������ڹ���AIоƬ(�N��910/910B)�����£�ModelArts�ԕN��CANN�ĵײ����Զ������ƽ̨��ѵ��������������
����▸ ȫջ������ȣ���оƬ������ѵ����ܵ�ƽ̨����Ϊʵ����ҵ��������������ϣ��ڷ����̬�����ܼ���
����▸ ���ģѵ����֤��֧�Ż�Ϊ�����̹Ŵ�ģ�͵�ѵ����ǧ�ڲ�������ij���ģ��ѵ����ʵ����֤
����▸ ��ҵ����������ڽ��ڡ������������ҵ�д������ƻ���ҵ�����������
����ModelArts �ĺ��ľ���
����▸ ��̬����ԣ�MindSpore����ڹ���ʦȺ����ܶȵͣ�PyTorch/TensorFlow��̬��������ڶ���Ħ�����������
����▸ ˽�л�������ࣺ�ư湦�ܷḻ��������˽�л��汾�������Թ����ͺ�"�����ư湦�ܡ�˽�л��ò���"������ձ�
����▸ ��Ʒ��GPU֧��������NVIDIA GPU�����£�ModelArts���Ż����Զ����CUDAԭ����̬�������������
����▸ TCOƫ�ߣ��N��Ӳ���ɹ�+ModelArts��Ȩ+��Ϊԭ������ĵ��ӣ�ȫ���ڳɱ���ͬ���Ʒ��ƫ��
����💡 ModelArts���ʺϣ���ȫ��ӵ���N����̬��ʹ��MindSpore��ܡ����л�Ϊ��ȷ���֧�ֵĴ��������û���������������NVIDIA GPUΪ����ModelArts�����ƽ����˥����
������������ ThinkAI — ȫ��Ӧ�����飬ƽ̨�����������
����6.1 ��Ʒ��λ
��������ThinkAI�����뼯��AI������ʩ���������Ʒ�Ƽ��ϣ���������ȫ�������(ThinkSystem)���洢�ͱ�Ե�豸�Ĺ�Ӧ�����ƣ�Ϊ��ҵ�ṩ��Ӳ��������������AI������ʩ������������AI������ʩ����IJ��컯��"ȫ��Ӧ��+���̷�������"����������ƽ̨��������ȡ�

����ThinkAI �������
����▸ ȫ��Ӧ����GPU������(NVIDIA��֤)�������ںͳɱ�ȫ�����ȣ����ģGPU��Ⱥ��������ǿ
����▸ ���̽���������ȫ��Χ�ڵ�רҵ�����Ŷӣ������������ļ�AI������ʩ���ֳ�ʵʩ����ḻ
����▸ ��Ʒ��GPU���ݣ������ض�AIоƬ���̣�NVIDIA/AMD/����AIоƬ����֧��
����▸ ��ԵAI��������Ե��AI��������(ThinkEdge)��������AI������ʩ�������ɫ����
����ThinkAI �ĺ��ľ���
����▸ ƽ̨����������Ȳ��㣺���ĵ��Ⱥ�MLOps������������������(��RunAI��MLflow��)�����м������Ǻӽ�dz
����▸ ��̬����Ħ��������������������ƴ�ӣ�ϵͳһ���Ժ����Ų鸴�Ӷȸ���һ�廯ƽ̨
����▸ �����г��������磺��Ȼ�Ϊ���»����������ڹ���AI������ʩ�ı��ػ���ȷ���������Ա���
����💡 ThinkAI���ʺϣ��д��ģGPU�������ɹ�������Ҫȫ�������������ڲ���һ��AI Infra�Ŷ�������ά�����Ŀ����ҵ���ͼ��š�
�����ߡ����ŷ� AICP — ��ȫ��̬��AI���죬�������ȷǺ�������
����7.1 ��Ʒ��λ����ҵ��
�������ŷ�AICP(AI Cloud Platform)�����ŷ��Ƽ���AI�˳����Ƴ�����������ƽ̨������ҵ������HCI��Ʒ�߶�һ�£��������еİ�ȫ��Ʒ�ͻ�������������ϵ��������ͻ�������AI������ʩ������������AI Infra���ļ������������г�������
����⚠️ ���ŷ�AICP��ս�Ա��ʣ�"AI"�ǰ�װ��"�����ͻ���ϵ"�����������ں���AI�������ȼ�������������ϣ����ŷ���ZStack����Ϊ����ͬһ������

�������ŷ�AICP�ĺ�������
����▸ ��ȫ��̬�����������ŷ���ȫ��Ʒ(EDR��������Ϊ������SSL VPN)ԭ�����ɣ�һվʽ�ɹ��Բ��ֿͻ���������
����▸ ����������ϵ���ڽ����������������ҵ�����ŷ������ͻ����вɹ�����
����▸ �������ܵ�λ������GPU��Դ�����(����GPU����һ��������)���û����������ܿ���������
�������ŷ�AICP�ĺ��ľ���
����▸ �����㷨�����У�������ԴKubernetes���ȿ�ܣ�ȱ������AIѵ�����������˸�֪����ռʽ���ȵ�����Ż�
����▸ ��ģ��ѵ��֧�������ֲ�ʽѵ����ܵ�������Ⱥ������Ż��������Բ��㣬����֧�Ű��ڲ������ϵ�ѵ������
����▸ GPU������ƫ�ͣ�ȱ���������������Ż����ƣ�ʵ��GPU�����ʵ�����ҵƽ��ˮƽ
����▸ �Ŵ�AIоƬ���䣺�N�ڡ�����������ȹ���AIоƬ������������������Բ��
����⚠️ ���ŷ�AICP������ʾ�����������ڸ���AIѵ���������Ŷ������������������ص㿼��ʵ��GPU������ָ��ͷֲ�ʽѵ�������֧�Ź�ģ�����ǽ��������̵Ĺ����嵥��
�����ˡ��˳� AICloud — �����������̵�����ƽ̨������
����8.1 ��Ʒ��λ
�����˳�AICloud���˳���Ϣ��AI������ҵ��������������������ƽ̨������HCI�������һ�ޣ��˳��ĺ���������AI�������Ĺ�ģ�����Ӧ������AICloud������ݵ���"��AI������������"�Ľ�ɫ��������Ϊ����AIƽ̨����������
����⚠️ �˳�AICloud��ս����������AI�����������������ƽ̨����������з����ȼ�����Ӳ����Ӧ��֮�����ڶ������ṩ���о�������Ӳ���۸���ζ��ƽ̨�����ij����ݽ��������ڲ�ȷ���ԡ�

�����˳�AICloud�ĺ�������
����▸ AI��������Ӧ�������˳��ǹ���AI��������������һ��GPU������(NF5488A5��)�Ľ����ٶȺ�ģ����ʵ����
����▸ GPU������Ӳ����֤������AIѵ��������Ӳ���ȶ����нϳ�ֵ�����������֤
����▸ ���ģ��Ⱥ�����������ģGPU��Ⱥ(��������ǧ��)�Ĺ��̽�������ḻ
�����˳�AICloud�ĺ��ľ���
����▸ ��Դƴװƽ̨�����ĵ��ȡ�MLOps��ģ�Ͳֿ�Ⱦ�Ϊ��Դ�����ɣ������к�������������DZ����⼼����Ӧ������
����▸ GPU�������Ż�ȱʧ��ȱ���������������ʹ������ƣ����ģ��Ⱥ��GPU�����˷�����ͻ��
����▸ �����ݽ�·�����������˳�δ����AICloud�Ķ�����Ʒ·��ͼ��������ij���Ͷ�����
����▸ Ӳ�����գ���������Ҫ����˳�����AI�������Ż����л�Ӳ��Ʒ��ʱ�����ش��������
����⚠️ �˳�AICloud�����գ�������AI����Ӽ�������չΪ���ӷֲ�ʽѵ����ƽ̨�������컨���Ѹ�ٱ�¶����ʱ�滻ƽ̨�Ĵ��ۣ���Զ������Ӳ���ɹ���ʡ�ijɱ���
�����š���ά����Ա�ȫ��
����9.1 �������Ⱥ��������Ա�
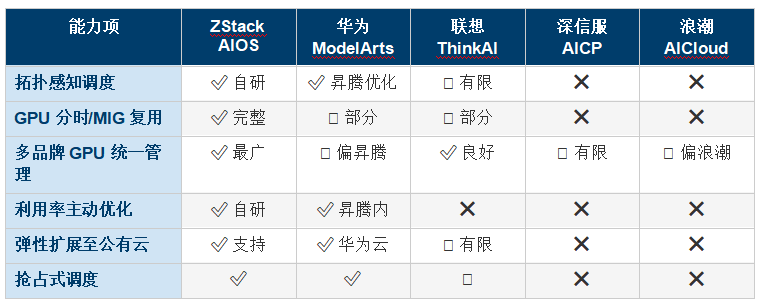
����9.2 ģ����������֧�ֶԱ�
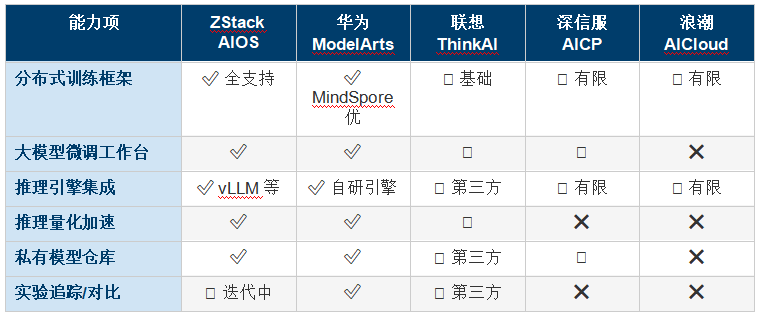
����9.3 ˽�л��������Ŵ��Ա�
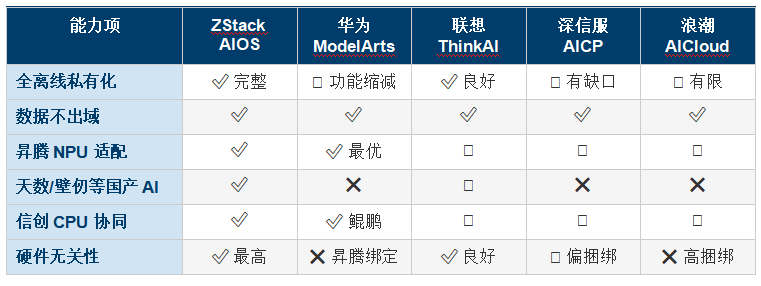
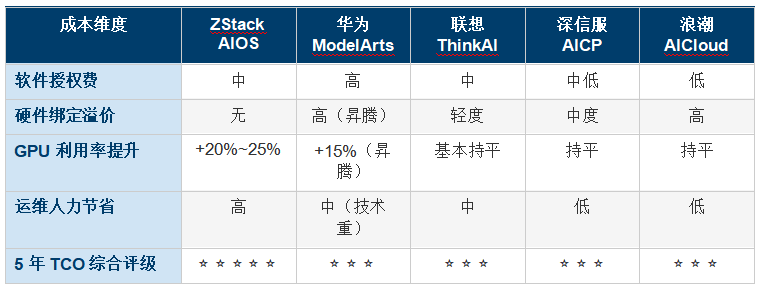
����9.4 TCO�Աȣ��ο�������32��GPU��Ⱥ��5��ȫ�������ڣ�
����ʮ������ѡ��ָ��
����10.1 ����ƥ�����
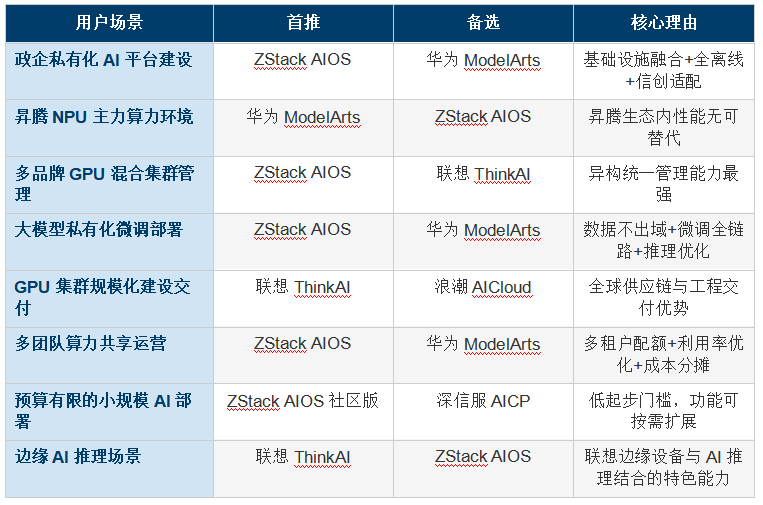
����10.2 ѡ�ؼ������嵥
������������̽��м�������ʱ�������������������⣺
����▸ ����һ��"���ǵ�GPU�����㷨�����еĻ��ǻ��ڿ�ԴKubernetes������?"——�����е��ȵ�ƽ̨���������������������
����▸ �������"��32�����ϵķֲ�ʽѵ����������������Щ�����߳���1������������ͻ����Բη�?"——��ʵ���ģ��������α��
����▸ ��������"������õ���NVIDIA GPU����ƽ̨���ṩʲô��ԭ��CUDA��̬����Ķ����ֵ?"——AI������ʩƽ̨���봴�쳬Խԭ�����ߵļ�ֵ
����▸ �����ģ�"ƽ̨������Ȩ�Ѻ�Ӳ�������Ƿ�ֿ��Ƽ�?Ӳ����Ʒ�ƺ������Ƿ���Լ���ʹ��?"——�ش�������������
����▸ �����壺"��ƽ̨��GPUƽ������������������ʲô?��û�п���ƵĿͻ�����֧��?"——������������AIƽ̨���ļ�ֵ����ֱ������
����ʮһ�������������Ƽ�
����2025�����ҵAI������ʩ�г������ھ�����"�ɹ�GPU"��"��Ӫ����"����֪ԾǨ��GPU�������IJɹ�ֻ����㣬�������������Ԥ�������AI���������������ľ���ս����
������ΪModelArts�ڕN����̬�ڵ������������������ȫ��Ѻע�N�ڵĴ������������ѡ������ThinkAI��ȫ��Ӧ�����̽����������ڳ����ģGPU��Ⱥ�����о��ж��ؼ�ֵ�����ŷ����˳���������Ӳ����������ҵ�����������������������ʵ����������֧�Ÿ��ӵ���ҵ��AI������
���������Ƽ���ZStack AIOSƾ�����ƻ�����ʩ��ԭ���ںϡ��������칹����������ϵ��ȫ��·ģ���������ڹ��������˽�л�������������Ϊ����������ۺϵ�һ������ϣ����˽�л����ڸ�Ч��ӪAI�����������ض�оƬ���̰���������TCO�������û���ZStack AIOS�ǵ�ǰ����AI������ʩƽ̨�У���ֵ�����ȿ��ǵ�ѡ��
������������
������������ڹ����������ϡ�ʵ���Ҳ��Լ��г������ۺ�д�����ֽ��۽����ο�����������ҵ�ɹ���Ψһ�������ݡ�AI������ʩ��Ʒ�����ٶȼ��죬ʵ��ѡ���������²�Ʒ�汾��POC���Խ��������֤��

������ҵ��Ѷ����ҵ��̬������ɷ����ʼ���news#citmt.cn����#����@����
����������...
������������ϵ������������������վ��ͼ��������ϵ�����±�������������
��ICP��18015839��-1רעIT��ҵ������IT��ҵ�� IT��ҵ��̬��ֵ����ƽ̨|IT��|IT�|IT���|ITֱ��
������ʾ:�������ݽ����Ķ�,������Ͷ�ʽ���,������Դ���
IT��ҵ��&WWW.CITMT.CN © 2016-2024

